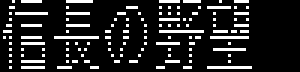
パーソナルコンピューターPC-8801は、カラー8色で640×200ドットの表示能力を持っている。
このとき、テキストは英数字と一部の記号、カタカナしか使えない。
そこで漢字とかなを表示できるようにした昔話をしよう(グラフィック扱いだけど)。
昔の話を引っ張り出してくるのは単純にネタ不足だからである。
16×16ドット(640x400モード時)
![]()
当時、一般的に全角文字は一文字16x16ドットで構成されていた。
PC-8801はSR以降に付属する日本語BASICを使えばこのようなテキスト表示が可能だが、そのかわりカラー表示ができなくなる。漢字が使える分だけ、フリーエリアも減る。
(上の画像はフォトショップでMSゴシックを使って仮に再現してみたもので、実機のデータとは異なる)
16×16ドット(640x200モード時)
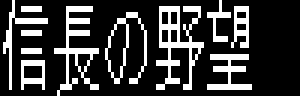
そのため、多くのソフトでは640×200モードで漢字を使うことになるが、ドット比が1:2なので、上画像のように文字が縦長になってしまう。
しかもテキストとしては扱えず、グラフィックとしてVRAMにデータを書き込むだけだった。重ね合わせ処理をしたいときなどは、重ね合わせルーチンを独自に実装しなければならなかった。
16×8ドット(640x200モード時)
![]()
縦長の文字では当時の狭いパソコンの画面を圧迫して多くの文字を表示できないので、縦2ドットづつAND処理して半分に潰し、16x8ドットにする方法がよくみられた。
16×8ドット(スキャンライン風)
![]() 見づらいと思われるかもしれないが、当時のCRTのスキャンライン風にしてみると、そこそこ読めることがわかる。
見づらいと思われるかもしれないが、当時のCRTのスキャンライン風にしてみると、そこそこ読めることがわかる。
16×10ドット
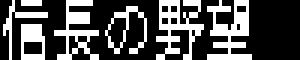
それでも読みづらいことには変わりない。そこで対策として当時の光栄のスタッフさんが考え出した(と私が勝手に思っている)のが上のフォントだ。

16×16ドットのうち、8ドット分だけ縦に圧縮して16×12ドットにするという方法だ。上の図の、赤い部分の縦2ドットを1ドットに圧縮している。
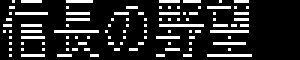 スキャンライン風に表示するとこうなる。
スキャンライン風に表示するとこうなる。
16x16よりは小さく、16x8ドットよりは読みやすい。
![]() 1ドットを1ピクセルの原寸表示にした。当時の標準の14インチCRTで見るともっと大きく見える。
1ドットを1ピクセルの原寸表示にした。当時の標準の14インチCRTで見るともっと大きく見える。
という解析を、高校生のときにしてました。
こーいうことばっかりやってたから浪人するのだ(汗)。
とにかく解析して表示のアルゴリズムはわかったので、漢字コードを呼び出して16x16ドット→16x10ドット変換ルーチンを組んでみた。ルーチン自体はBASICだと遅くて話にならない。
ニーモックで書いてハンドアセンブルして200バイトくらいだったかな。
既存のかな表示ルーチンを改造しただけの代物で、縦圧縮する行を指定する処理を入れただけ。これが私が作った唯一の自作マシン語プログラムだった(笑)
PC-8801mk2SR以降は3プレーン同時表示できるので、BASICから呼び出してもそこそこの速さだった。
以上、平成元年ごろの昔話でした。
そのうち途中まで作った画面写真を載っけるね。